Understanding OpenManus: How Agent Systems Work
Discover how agent systems like OpenManus plan, coordinate, and adapt to complete complex tasks
Recently, a new company called Bufferfly Effect has raised 75 million USD from well-known investors such as Benchmark Capital. You might not have heard of this company, but you probably have heard its LLM agent product - Manus, which went viral on social media last month. I was given an invitation code to Manus by my investor friend during its debut in early March. As an agent novice user, I was quite impressed by how the product was constructed, including its automation capability and user experience. I asked Manus to help me plan a trip to Japan and Manus demonstrated its work progress step by step and it is able to deliver a complete trip plan after 20 minutes (the speed can still be improved). Just like DeepSeek, Manus showcased what it actually did in a sandbox, being it a terminal or browser. I believe this kind of visualization of chain of thought & action is what makes this product favoured by many users.
As a researcher in machine learning system, I spend my time on how to make AI more efficient and have limited knowledge on how agent systems work. Luckily, the open-source project OpenManus has made efforts to reproduce Manus and this gives me a opportunity to take a look at the inner working of agent systems.
This blog post is a summary of my exploration on OpenManus while reading through the source code and I hope it gives you a brief introduction to agent systems if you are also a beginner like me.
Do note that the Open-Manus project is constantly evolving and my blog is only specific to its codebase in April 2025.
Prerequisites
Before we dive into the details of OpenManus, there are some background knowledge that you should know.
1. Agent System
An agent is an autonomous system designed to perceive its environment, make decisions, and take actions to achieve specific goals without continuous human intervention. With the advent of ChatGPT, it is a common goal for the AI community to build a smart personal assistant that can help with daily tasks for everyone. Agent systems are the key to achieve this goal. Simply speaking, an agent system can help to plan, reason, make decision, and take action on your behalf to achieve a specific goal for you.
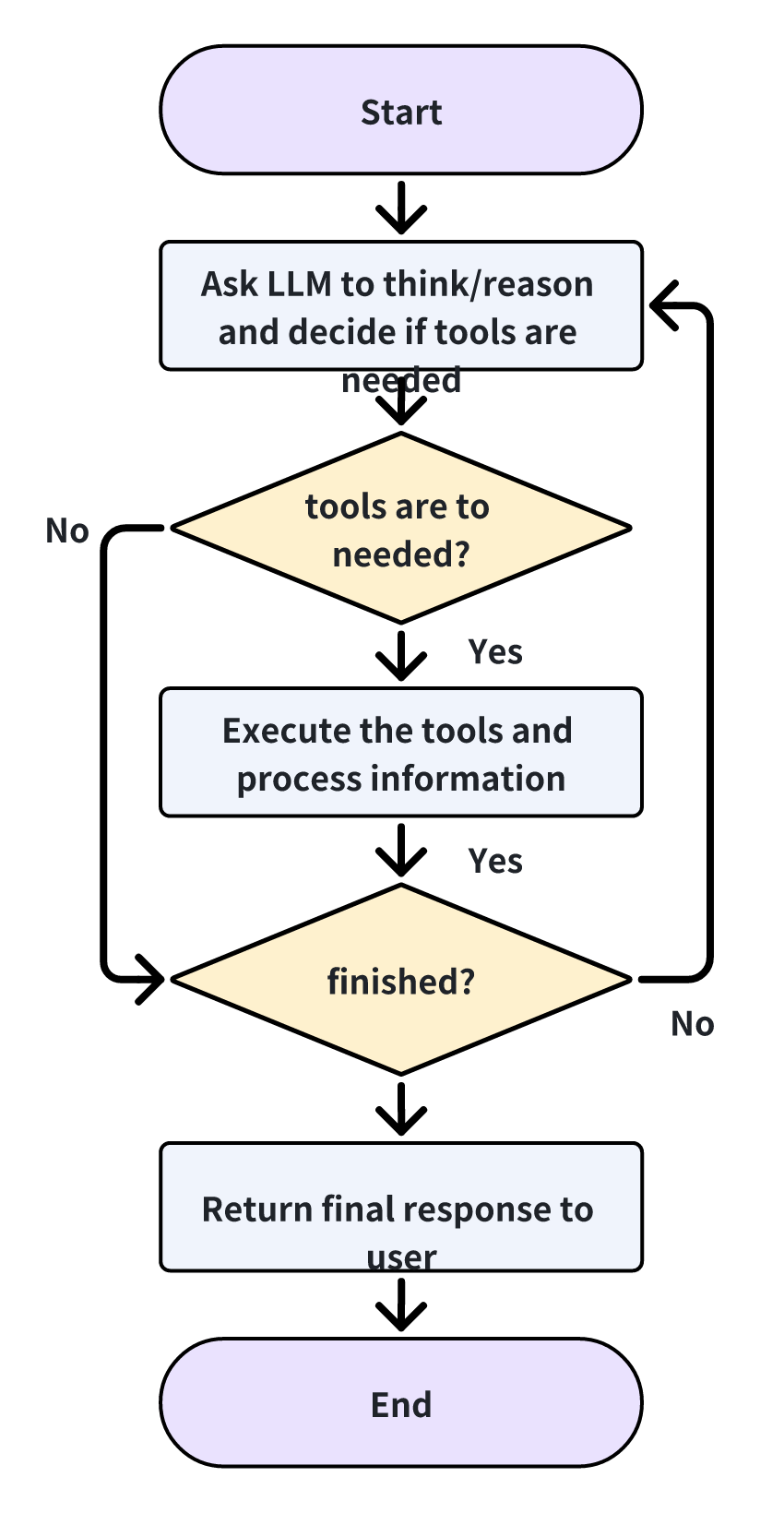
2. ReAct Agent
ReAct agent is a simple but useful concept in agent, proposed by the OpenAI researcher Shunyu Yao. It combines both reasoning and execution in an interleaved manner to improve the agent's performance in tasks. ReAct agents iteratively think and reason about the current task, and then decide whether to use tools to complete the current task. If the tools are needed, it will take the action and update the internal state. The general workflow is shown below.
3. Function Calling
Function calling is LLM's ability to decide which function/tool to use and what parameters to provide to the function call when given a context and a list of function descriptions. This allows the model to dynamically select the suitable tools for a specific task. The user needs to define functions in a specific format such as:
pythonfrom openai import OpenAI client = OpenAI(api_key="your-key") weather_tool = { "type": "function", "function": { "name": "get_weather", "description": "Get current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "City and country e.g. Bogotá, Colombia" } }, "required": [ "location" ], "additionalProperties": False } } }
We can then call the OpenAI APIs with the tools field.
pythonresponse = client.chat.completions.create( model="gpt-4.1", messages=[{"role": "user", "content": "What is the weather like in Paris today?"}], tools=[weather_tool] ) print(response.choices[0].message.tool_calls)
The API will return a response like below. The response contains the name(s) of the function(s) to use, and the corresponding parameters structured in json format. In this way, the developer can look up for the actual function code and execute that function with the given parameters.
python[ ChatCompletionMessageToolCall( id='call_xFu1qgsnPzzviCxNvDNcXf41', function=Function( arguments='{"location":"Paris, France"}', name='get_weather' ), type='function' ) ]
4. Browser-User
Browser-use is a python package which manipulates and interacts with a web browser in real time. It is built upon the testing framework playwright. In browser-use, it has its own agent system built in the package, however, OpenManus mainly uses it Browser function and has written its own browser interaction logic.
Code Walkthrough
In this section, I will briefly go through the high-level project structure and explain how each component works. Afterwards, I will discuss how each components work together to deliver a complete agent system.
Core Modules
This subsection cover the major modules in the OpenManus project. Each module is a collection of classes responsible for different functionalities, which will be covered in detail below.
Agents
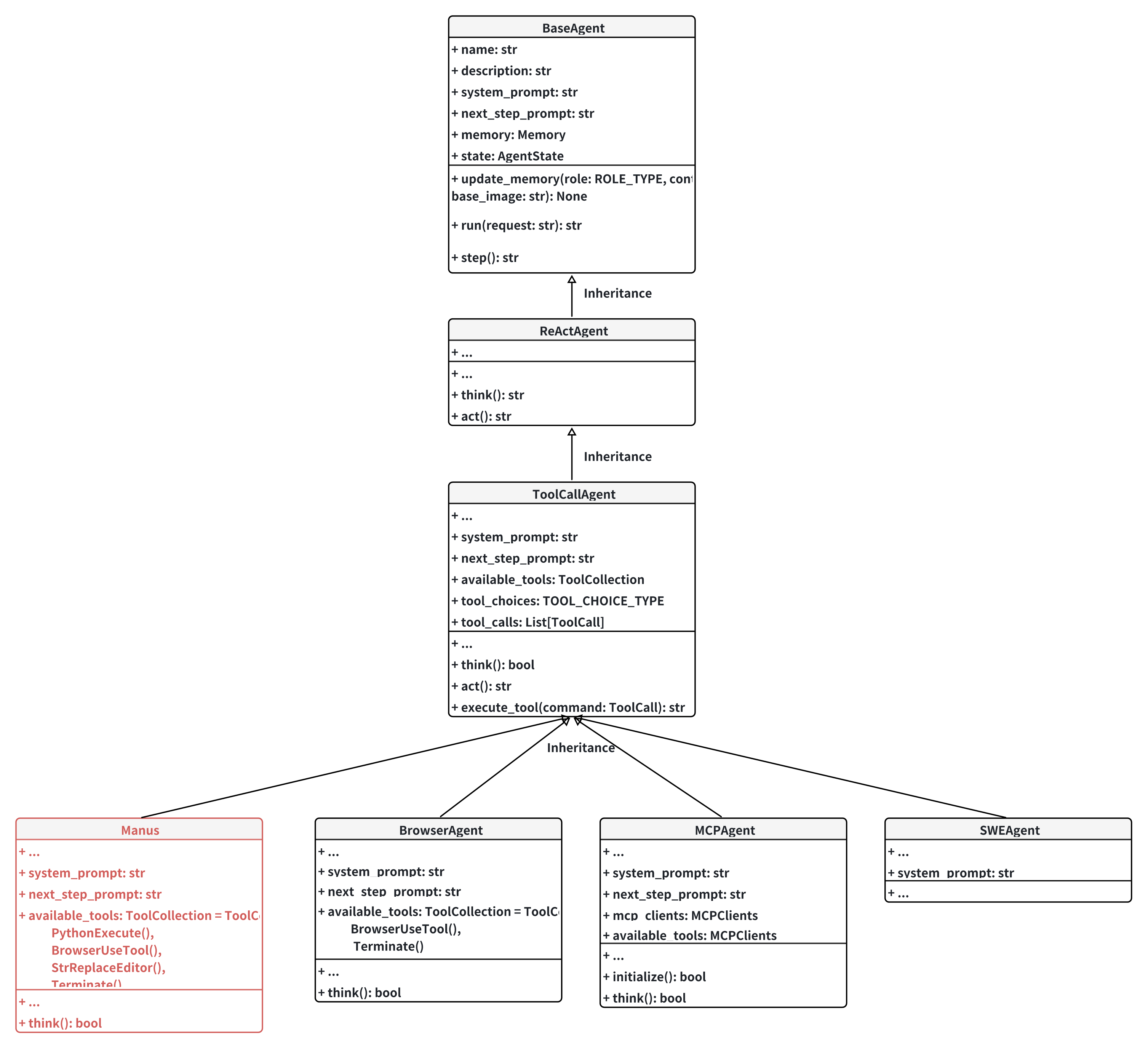
The agent module is the entrypoint of the agent system. It is responsible for the overall workflow of the agent system. As shown in the diagram above, the agents are organized in a hierarchical structure and the ReActAgent and ToolCallAgent define the core logic flow for task automation. Each class' duty is explained below:
-
BaseAgent
This is the most fundamental class of an agent, it mainly takes care of the properties and states of the agent. For example, it has a name and description and also a system prompt to interact with the LLMs. The run method is the entrypoint of this agent, in run, the agent basically runs the step method repeatedly until its agent becomes FINISHED or IDLE.
- Finished: means the agent has finished the task
- IDLE: means the agent has not finished the task but has reached the max number of steps, so it is forced to terminate
The
stepmethod is an abstract method which the inherited classes will implement to define how each iteration goes. -
ReActAgent
This class inherits BaseAgent and implements the step method. It uses the ReAct agent idea to combine both reasoning and action. Its step logic is like:
pythonasync def step(self) -> str: """Execute a single step: think and act.""" should_act = await self.think() if not should_act: return "Thinking complete - no action needed" return await self.act()Both the think and act methods are abstract.
-
ToolCallAgent
ToolCallAgent includes the use of tools in the thinking and acting stages of a ReAct agent. In the thinking stage, it passes the available tools to LLM and let LLM to choose the suitable tools to use and the corresponding parameters via functional calling.
pythonasync def think(self) -> bool: ... response = await self.llm.ask_tool( messages=self.messages, system_msgs=( [Message.system_message(self.system_prompt)] if self.system_prompt else None ), tools=self.available_tools.to_params(), tool_choice=self.tool_choices, ) ...In the acting stage, the agent will call the tool in order with the parameters given in the LLM response. The tool outputs are concatenated as the final output.
pythonasync def act(self) -> str: """Execute tool calls and handle their results""" if not self.tool_calls: if self.tool_choices == ToolChoice.REQUIRED: raise ValueError(TOOL_CALL_REQUIRED) # Return last message content if no tool calls return self.messages[-1].content or "No content or commands to execute" results = [] for command in self.tool_calls: # Reset base64_image for each tool call self._current_base64_image = None result = await self.execute_tool(command) if self.max_observe: result = result[: self.max_observe] logger.info( f"🎯 Tool '{command.function.name}' completed its mission! Result: {result}" ) # Add tool response to memory tool_msg = Message.tool_message( content=result, tool_call_id=command.id, name=command.function.name, base64_image=self._current_base64_image, ) self.memory.add_message(tool_msg) results.append(result) return "\n\n".join(results) -
Manus
Manusis the main agent in the Open-Manus system. It is different from the ToolCallAgent as it processes the prompt a bit before thinking. As shown in the code below, Manus will check if browser was used in the last 3 messages. If yes, it will format the prompt by injecting the current browser's state information (e.g. text, buttons, tabs, etc.) into the prompt. This allows the LLM to do a better job in function calling as it is aware of the content on the browser and can choose what action to perform on the browser.pythonasync def think(self) -> bool: """Process current state and decide next actions with appropriate context.""" original_prompt = self.next_step_prompt recent_messages = self.memory.messages[-3:] if self.memory.messages else [] browser_in_use = any( tc.function.name == BrowserUseTool().name for msg in recent_messages if msg.tool_calls for tc in msg.tool_calls ) if browser_in_use: self.next_step_prompt = ( await self.browser_context_helper.format_next_step_prompt() ) result = await super().think() # Restore original prompt self.next_step_prompt = original_prompt return result -
BrowserAgent
This agent is implemented, but I don't see it being used anywhere. Moreover, its functionality significantly overlaps with the BrowserUseTool in 2. Tool, so I will skip it for now.
-
MCPAgent & SWEAgent
MCPAgent uses MCP servers as tools, and SWEAgent is just a different system prompt, so we skip them here.
Tools
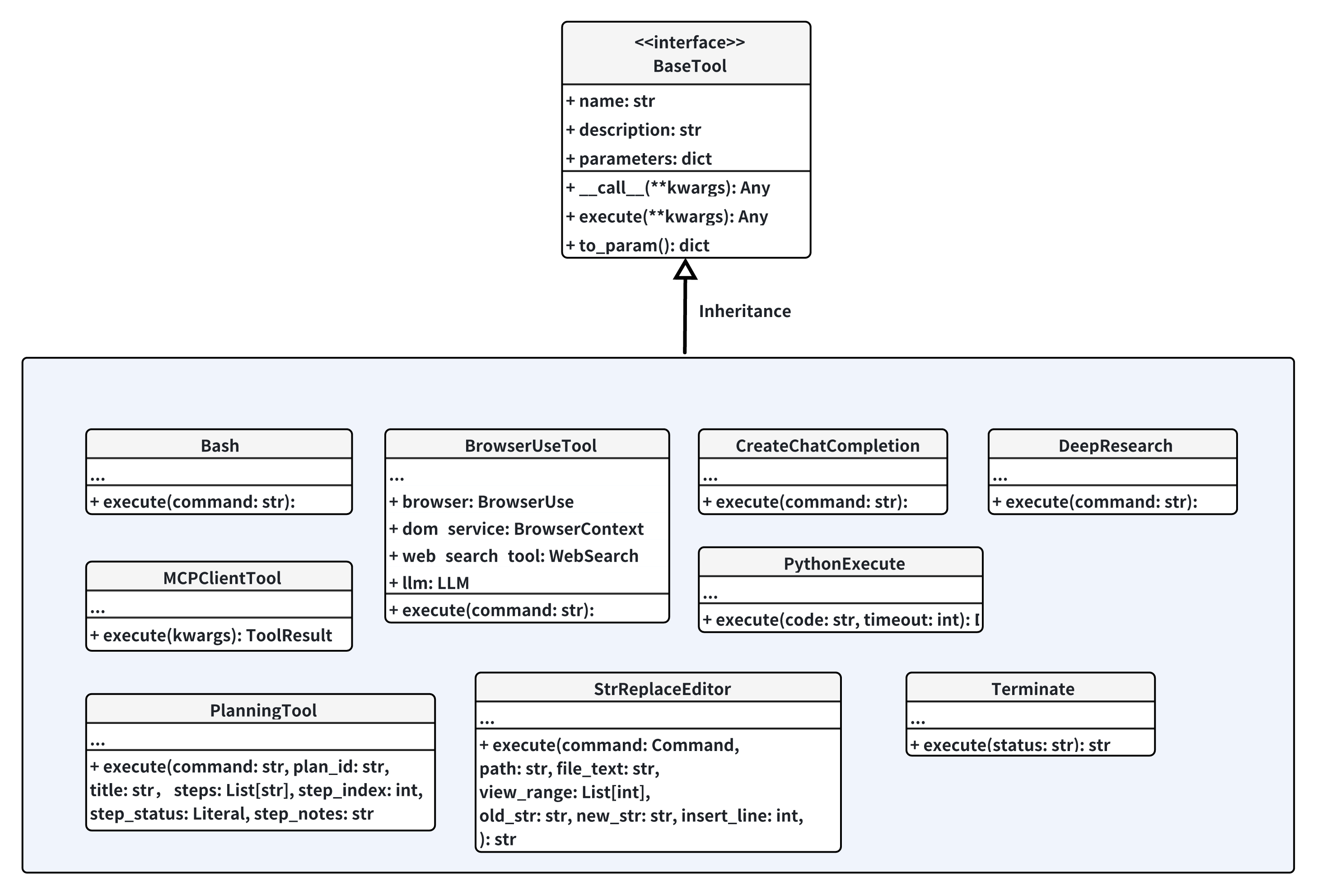
The tools module implements a collection to external tools which can be used by the agent to retrive information and reason.
-
Bash
This tool creates a bash session using
asyncio.create_subprocess_shell, and receives bash command for execution. It then return the log in shell as output. -
BrowserUseTool
It relies on the browser-use package to control the browser and execute commands such as
go_to_url,click_element,input_text, and so on. If the comand is extract_content, it will use markdownify to convert to the page content into Markdown text and use LLM to extract the text according to a goal given by the inputs. -
CreateChatCompletiton
This tool does not actually perform chat completion, instead, it only extracts the necessary fields from a response data. When calling
execute, the tool receives a list of strings (field names) and the response data and only keep the part of the data in the response according to the required fields. -
DeepResearch
The Deep Research tool is a tool that can be used to perform a complete research cycle. It can be seen as an extension of the chat completion and web search by following the following steps:
- Optimize the search query using LLM
- Perform a complete research cycle:
- Search on the web
- Extract insights using LLM
- Generate follow-up queries and research with follow-up queries
- Return research summary stored in context
-
MCPClientTool
Init a MCP connection and send request to the MCP server.
-
PlanningTool
This tool does not perform planning on its own, it is more like a planning manager, which takes care of the CRUD operations of planning.
-
PythonExecute
It takes a code string and executes this piece of code in a new process and returns its output as result.
-
StrReplaceEditor
This tool is used for viewing, creating and editing files locally or in sandbox. This class basically abstracts the file operations and expose these operations as commands to the client calling this tool.
-
Terminate
This is a dummy tool, which only returns an ending message to convey the status of the task.
-
WebSearch
It basically conducts search on all available search engines including google, baidu, duckduckgo, and bing. Google is set as the preferred engine so it will be used first. These search engine results will only include meta information like position, title and URL. The tool will then fetch the content of the web pages and return as response.
Sandbox
The sandbox module is responsible for creating an isolated environment for the agent to execute the task. It is a wrapper for the Docker SDK and provides a unified interface for the agent to interact with the sandbox.
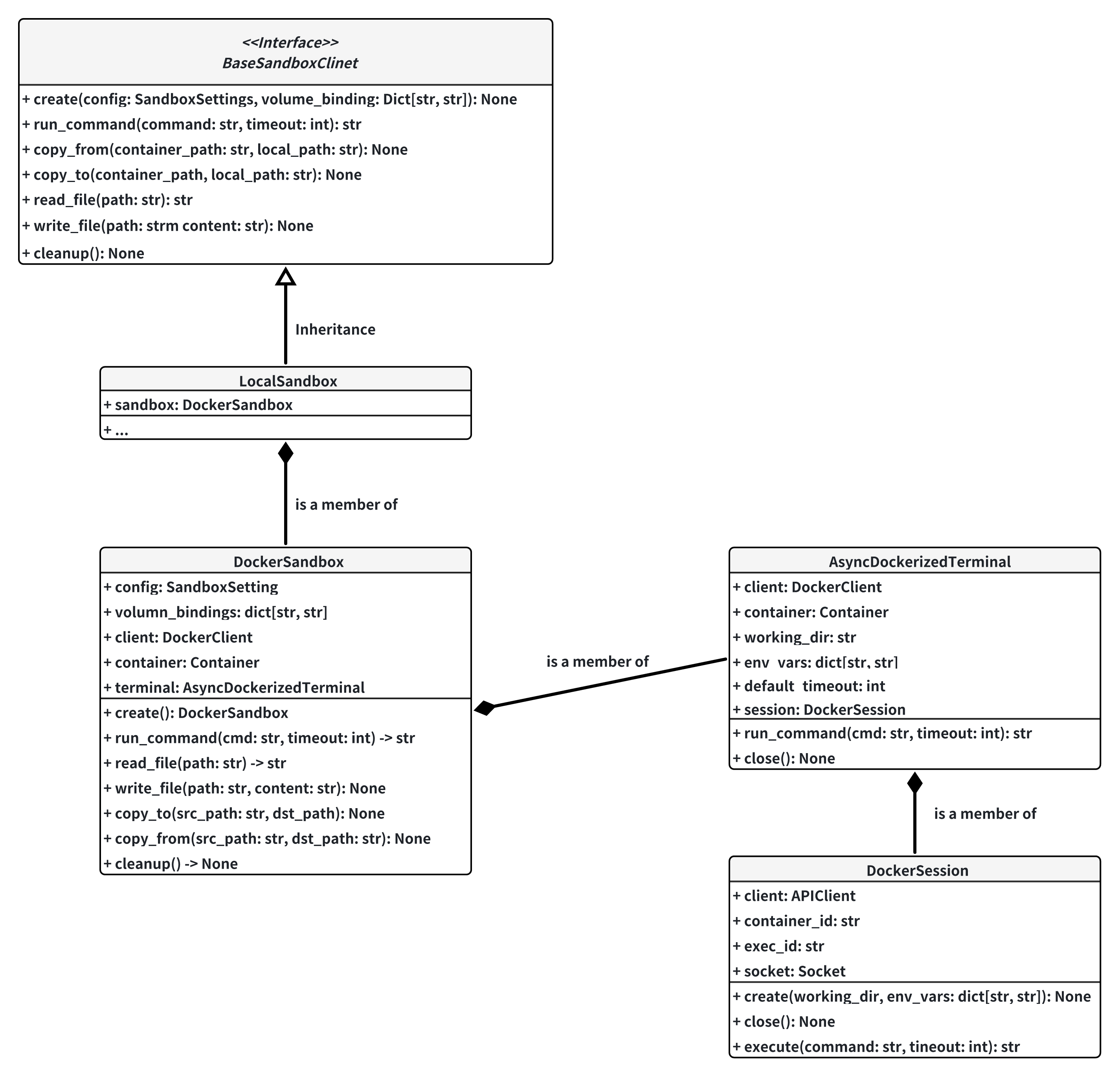
-
BaseSandboxClient
This is an interface for sandbox, which defines the methods for child classes to implement, these methods include file operations and run_command.
-
LocalSandbox
This is a child class for BaseSandboxClient and also a wrapper for DockerSandbox. It call the methods in DockerSandbox to implement the abstract methods.
-
DockerSandbox
This class is wrapper for the Docker Python SDK as it contains a DockerClient object, it use this client to implement methods such as file operations. run_command is achieved by using the AsyncDockerizedTerminal.
-
AsyncDockerizedTerminal
This object basically creates a Docker container session and send the command to the session and retrieve the command output.
-
DockerSession
This object uses the Docker APIClient to interact with an existing container. It can exec into the container by exec_create to get an interactive session. Then, it uses exec_start to create a socket connection with the session, sending the command and retrieving console output via socket.
Memory
Memory is a module that manages the conversation history (context) of the agent. It is responsible for storing the messages and the states of the agent.
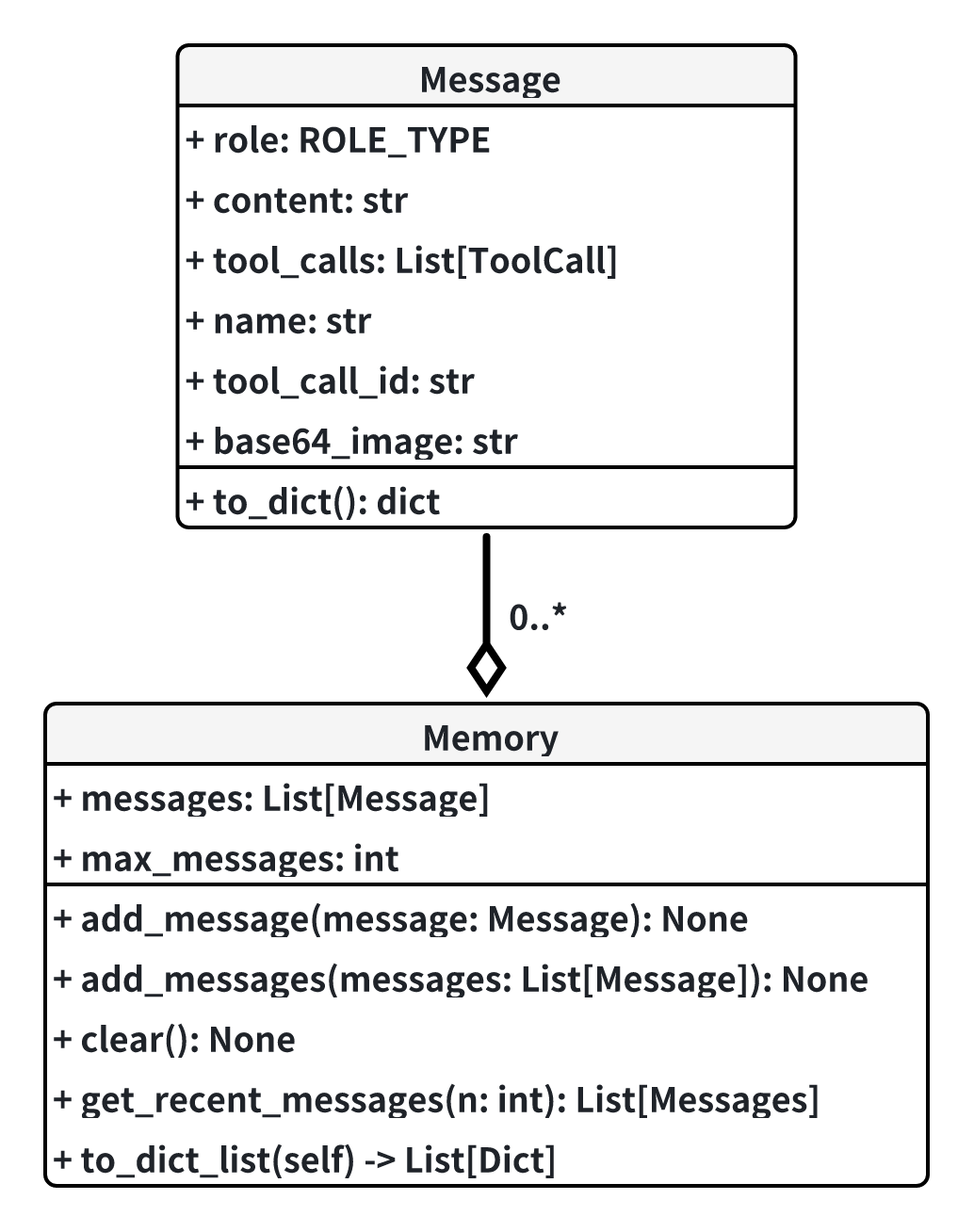
-
Message
Message represents the chat message in a conversation. It can be from the system, user, assistant or tool.
-
Memory
Memory is basically a list of messages in history. It is limited by the max_messagse size and uses a FIFO eviction policy.
Collective Logic
What is OpenManus' workflow?
Manus carries out work in 4 steps:
-
Initialization stage
Manus inherits the
ToolCallAgentclass, during initialization, it will set some basic properties such as name, system prompt, next step prompt and list the available tools it can use. In Manus, the available tools inlcudePythonExecute,BrowserUseTool,StrReplaceEditorandTerminate.pythonclass Manus(ToolCallAgent): """A versatile general-purpose agent.""" name: str = "Manus" description: str = ( "A versatile agent that can solve various tasks using multiple tools" ) system_prompt: str = SYSTEM_PROMPT.format(directory=config.workspace_root) next_step_prompt: str = NEXT_STEP_PROMPT max_observe: int = 10000 max_steps: int = 20 # Add general-purpose tools to the tool collection available_tools: ToolCollection = Field( default_factory=lambda: ToolCollection( PythonExecute(), BrowserUseTool(), StrReplaceEditor(), Terminate() ) ) special_tool_names: list[str] = Field(default_factory=lambda: [Terminate().name]) browser_context_helper: Optional[BrowserContextHelper] = None -
Thinking Stage
This is the first stage of a ReAct agent, Manus will think about its next move based on the current and recent messages. In Manus, it handles the browser-use specifically: if there is any recent use of browser, it will format the next step prompt,
browser_context_helper.format_next_step_promptwill inject the current states of the browser into the prompt, the states include URL, tabs, clickable elements and so on.It then calls its parent class
ToolCallAgent's thinking method. In this method, Manus calls LLM to think about the next action. at the same time, the available tools are given to LLMs for function calling as well, so LLM will select the suitable tools to use for the next action.
-
Acting Stage
In this stage, Manus calls the tools if there is any.
-
Looping Stage
The thinking and acting stages are wrapped in the run method of Manus. This method runs a for loop to repeat thinking and acting stages until the state becomes finished or the maximum step has been reached.
pythonasync def run(self, request: Optional[str] = None) -> str: if self.state != AgentState.IDLE: raise RuntimeError(f"Cannot run agent from state: {self.state}") if request: self.update_memory("user", request) results: List[str] = [] async with self.state_context(AgentState.RUNNING): while ( self.current_step < self.max_steps and self.state != AgentState.FINISHED ): self.current_step += 1 logger.info(f"Executing step {self.current_step}/{self.max_steps}") step_result = await self.step() if self.is_stuck(): self.handle_stuck_state() results.append(f"Step {self.current_step}: {step_result}") if self.current_step >= self.max_steps: self.current_step = 0 self.state = AgentState.IDLE results.append(f"Terminated: Reached max steps ({self.max_steps})") await SANDBOX_CLIENT.cleanup() return "\n".join(results) if results else "No steps executed" -
Cleanup Stage
In this stage, Manus will clear up the resources used during the task such as the browser.
How does OpenManus interact with the tools?
To understand this, we can separate it into two questions:
- How does manus know which tool to use?
- How does manus invoke the tool?
These two questions indeed correspond to the thinking and acting stages as mentioned above. During the thinking stage, Manus will use the function calling feature of the LLM API to let the model decide the usable tools and parameters. During the acting stage, Manus will iterate over the tool list and feed each tool function with its parameters and fetch the result.
How does OpenManus interact with the browser?
Manus does not use VLM to decide which elements to click or where is the URL bar. Instead, browser-use will return these information as browser states and the states are organized as a dictionary. For example, each clickable element in the DOM tree is converted to a string, and these states are given to LLM as context for the LLM to select which element to click.
pythonasync def get_current_state( self, context: Optional[BrowserContext] = None ) -> ToolResult: """ Get the current browser state as a ToolResult. If context is not provided, uses self.context. """ try: # Use provided context or fall back to self.context ctx = context or self.context if not ctx: return ToolResult(error="Browser context not initialized") state = await ctx.get_state() # Create a viewport_info dictionary if it doesn't exist viewport_height = 0 if hasattr(state, "viewport_info") and state.viewport_info: viewport_height = state.viewport_info.height elif hasattr(ctx, "config") and hasattr(ctx.config, "browser_window_size"): viewport_height = ctx.config.browser_window_size.get("height", 0) # Take a screenshot for the state page = await ctx.get_current_page() await page.bring_to_front() await page.wait_for_load_state() screenshot = await page.screenshot( full_page=True, animations="disabled", type="jpeg", quality=100 ) screenshot = base64.b64encode(screenshot).decode("utf-8") # Build the state info with all required fields state_info = { "url": state.url, "title": state.title, "tabs": [tab.model_dump() for tab in state.tabs], "help": "[0], [1], [2], etc., represent clickable indices corresponding to the elements listed. Clicking on these indices will navigate to or interact with the respective content behind them.", "interactive_elements": ( state.element_tree.clickable_elements_to_string() if state.element_tree else "" ), "scroll_info": { "pixels_above": getattr(state, "pixels_above", 0), "pixels_below": getattr(state, "pixels_below", 0), "total_height": getattr(state, "pixels_above", 0) + getattr(state, "pixels_below", 0) + viewport_height, }, "viewport_height": viewport_height, } return ToolResult( output=json.dumps(state_info, indent=4, ensure_ascii=False), base64_image=screenshot, ) except Exception as e: return ToolResult(error=f"Failed to get browser state: {str(e)}")
The LLM will then return the index of the element to click after function calling query, Manus will then get the element by index and perform click action.
pythonelif action == "click_element": if index is None: return ToolResult( error="Index is required for 'click_element' action" ) element = await context.get_dom_element_by_index(index) if not element: return ToolResult(error=f"Element with index {index} not found") download_path = await context._click_element_node(element) output = f"Clicked element at index {index}" if download_path: output += f" - Downloaded file to {download_path}" return ToolResult(output=output)
How does Manus manage its memory?
Manus adds the following content to memory in order:
- Before the thinking stage, Manusadds the user request content into memory at the beginning of the run method
- During the think stage, Manusadds the LLM response to memory. If there is any exception, the exception is added to memory as well.
- During the acting stage, Manus adds the tool response message to memory.
Conclusion
By walking through the fundamental ideas and some high-level code review, I hope that you should have a rough idea of how OpenManus works now. However, I can't say that everything in this blog post is correct as I am still a novice in agent, do let me know if there is any error to rectify.